VIDA released their merged Google and Microsoft building footprint dataset. As they describe it, “with 2,534,595,270 footprints, it is to our knowledge the most complete openly available dataset as of Sep. 2023. It covers 92% of Level 0 administrative boundaries, and is divided into 182 partitions”.
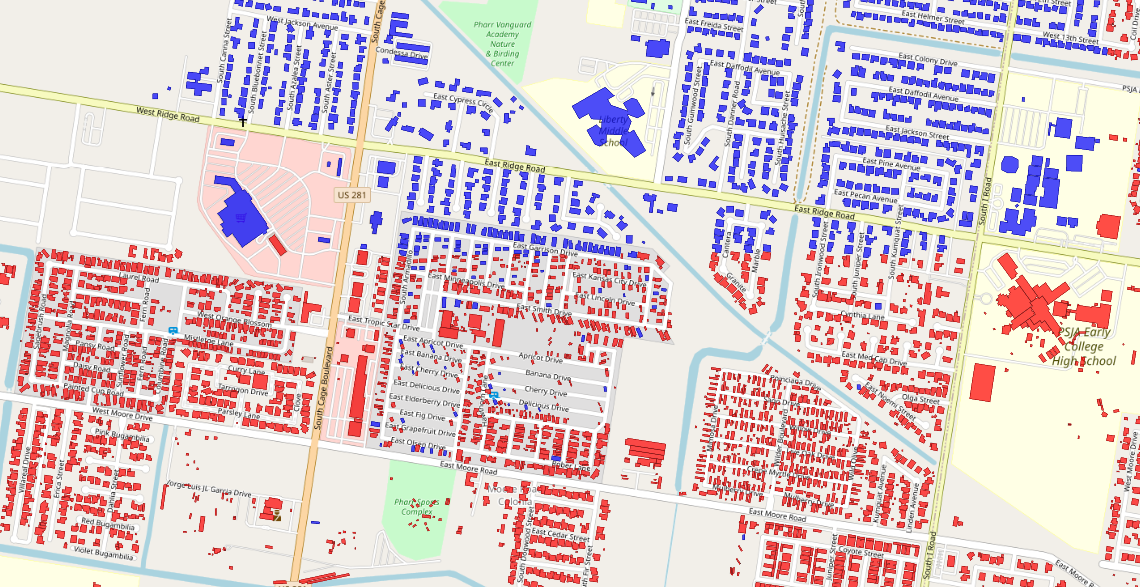
Due to my past work exploring how building footprints could be partitioned, I gravitated to that last section. How is this, even larger, dataset partitioned? In this case VIDA opted for a two-level partitioning strategy. First, the dataset is divided by country administrative level-0 boundaries (defined by Comprehensive Global Administrative Zones). The country is then sub-divided into partitions on S2 Cells, where each sub-partition has a cap of 20 million buildings. Each parquet file is named by the S2 ID of the cell, which allowed me to query the dataset, and generate this map of all of the partition footprints.
What can we learn from this map? It looks like what happens is that for each country a S2 Cell level is chosen. So all partitions in the United States share a common S2 Cell level (level XX), and all partitions in Indonesia another level (level YY). This level is likely chosen as the largest level that can be used, while maintaining the cap of no more than 20 million buildings in any partition.
Additionally, we can see that partitions between countries can share the same S2 Cell. For example in cell 0c, there are 19 counties that use this partition: BFA, CIV, CPV, DZA, ESH, ESP, FRA, GHA, GIN, GMB, GNB, LBR, MAR, MLI, MRT, PRT, SEN, SLE, TGO. Also partitions can overlap between countries, as child cells may exist for neighboring countries, for example United States uses S2 Cell 80d, and Mexico uses 80d4, a child cell of 80d.
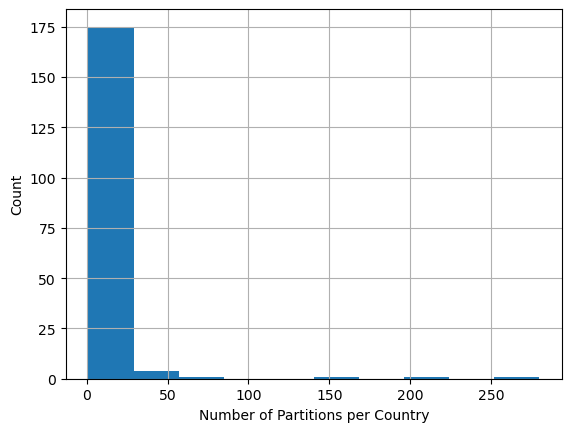
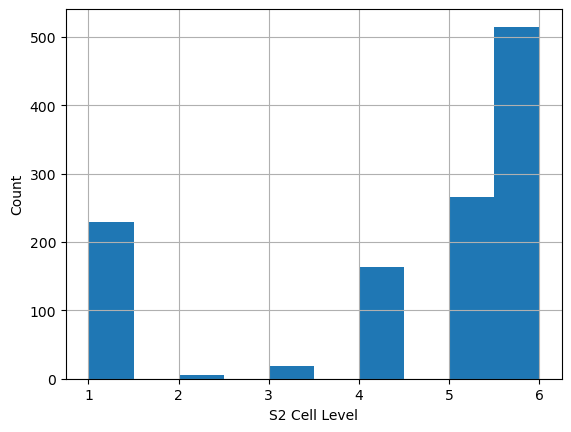
Looking at the partitions we can see that a majority of countries only have 1 partition for the entire country, but some have many. The same few countries that have a large number of partitions are the ones that also have the higher S2 Cell level.
What do I like about this partition method? #
Despite my critics, partitions on country bounds just makes sense for many people, and I can understand why this is the method that they persued. By dealing with countries, users do not have to query a service if they know what area they are working at. Also with the 20 million building cap, the total number of partitons is dropped to a small level, while most files still being fairly managable in size.
What do I not like as much? #
The limitation of countries boundry is a problem whenever you partition on a administative level, as I mention in my other post. No matter what these boundries are precise only to a level, some may not agree with the data producers view of borders, and cross border work is more work. Additionally, the densest area of any country will determin the S2 Cell level the data is partitioned at. This means that there could be areas where the partition size still is smaller than it could be.