Intro #
Google recently released their v3 dataset of building footprints, which has garnered significant attention. I find this dataset fascinating for two main reasons: its highly accurate predictions and its unique distribution approach. The dataset employs an intriguing partitioning scheme based on S2 Cells but is distributed in the form of CSV files, which may not be the most user-friendly format. Some of these compressed CSV files can reach sizes as large as 8 GB, as illustrated in the map below. Working with such large files in this format can be challenging, as it doesn’t allow for efficient parallel reading, necessitating the loading of the entire file to extract a subset of data.
Others have previously tackled the Google Open Buildings dataset, opting to either partition it by country or retain the original large partitioned files but convert them into a more cloud-native format. While partitioning by country seems logical, I ultimately found it to be too restrictive, given the various ways people might want to utilize the data. This approach makes sense if you have specific countries in mind and wish to extract data accordingly. However, if your analysis requires different country borders or spatial areas like watersheds that disregard political boundaries, you might end up retrieving more data than necessary.
Why S2 Cells? #
1) Unlike countries, S2 cells are nested heirachacle cells #
Each S2 cell contains 4 child cells. Each child cell is contained entirely in it’s parent cell. This is different from other popular cell index methods, such as the popular hexagonal cells of the H3 library. In H3 a cell is not entirely contained in it’s parent. This means that you cannot easily assign buildings to one cell in entirely, as they may overlap into others.
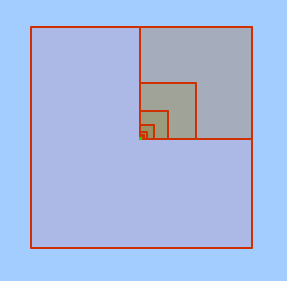
2) S2 ids are derived so that closed ids have a more similar value #
This is helpful when exporting for partitioned files based on the S2 id column.
3) The function for calculating if s2 cell id is contained in a parent is very fast and simple #
You can quickly manipulate a S2 cell id to check if it is contained in a known parent cell id. For more detail refer to the S2CellId Numbering (again) section of S2’s dev guide.
Partitioning the Dataset #
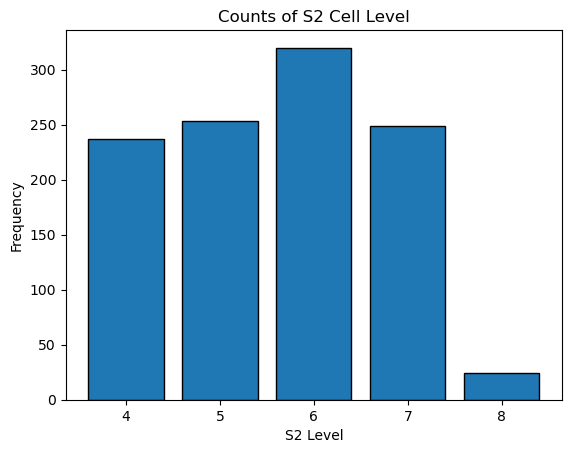
Using the 3 strengths of S2 cells above, I came up with a new plan for partitioning the Google Buildings dataset. My goal was to minizme the number of partitions, and ensure no partition has too few or too many buildings per partition. To do this, we will keep the original level-4 splits, and if any have more than 5,000,000 buildings, we will split into 4 child cells and check those against the buildings limit, spliting recursivlly until we don’t hit the limit or hit level 9.
In order to partition the dataset I used Google BigQuery export from the multiple CSV’s stored on Google Cloud Storage to partitioned parquet files. To do this, the S2 cell id for the building, and the level 4 S2 cell id were set for each building. The level 4 token was used to split the dataset into individually level-4 partitioned parquet files.
To further check and split level-4 cells with a building limit, I used dask-geopandas to load each level-4 parquet file, check the length, and iterate through child cells until the child cell has less than 5,000,000 buildings or we’ve hit level 9. We rely on strength #3 use the original S2 cell ids, and select the rows that match the child cell we are checking.
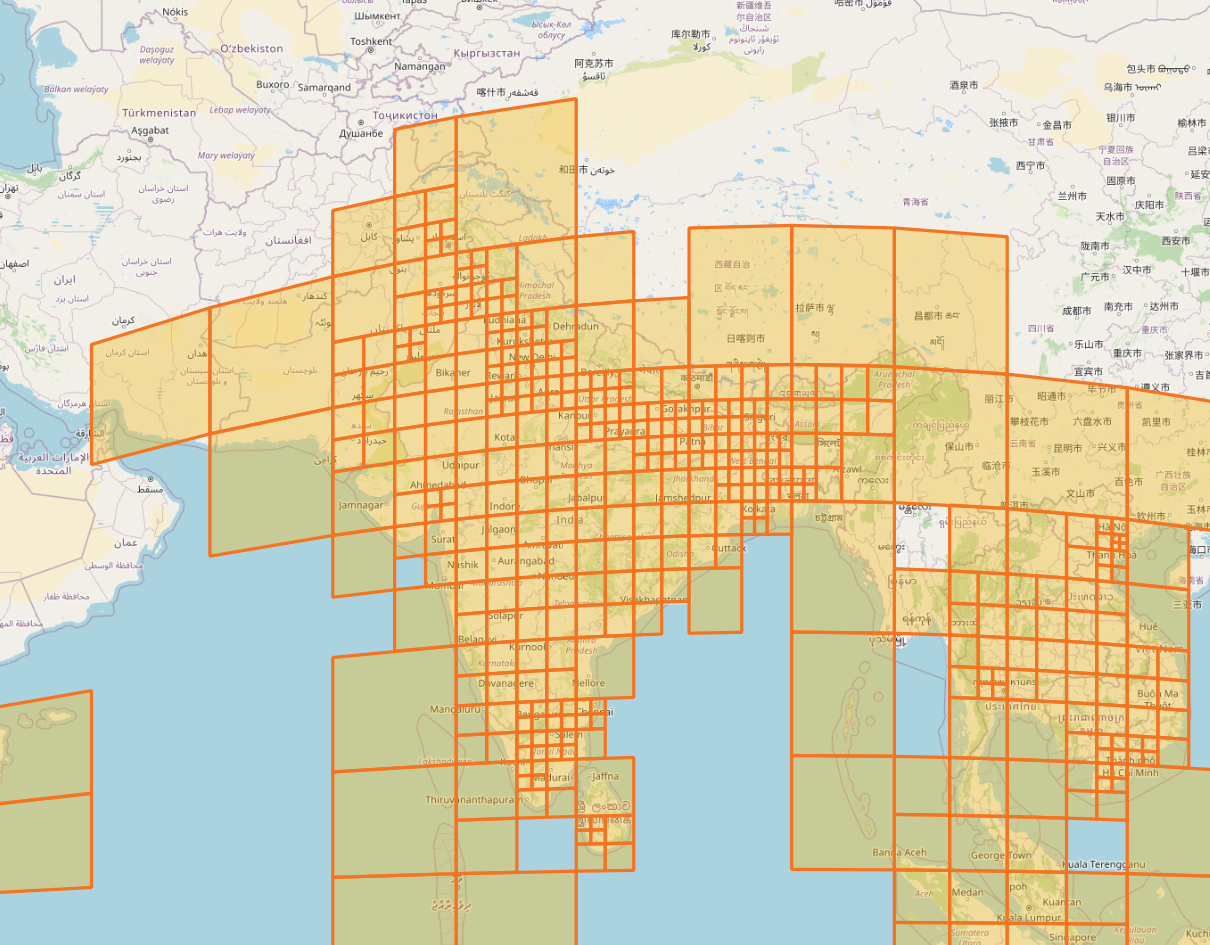
In this image, we can see how partition are handled across a range of population density (and thus building density). The densely populated northern India has small higher level S2 cells, while the less populated islands chains keep their original level 4 partition.
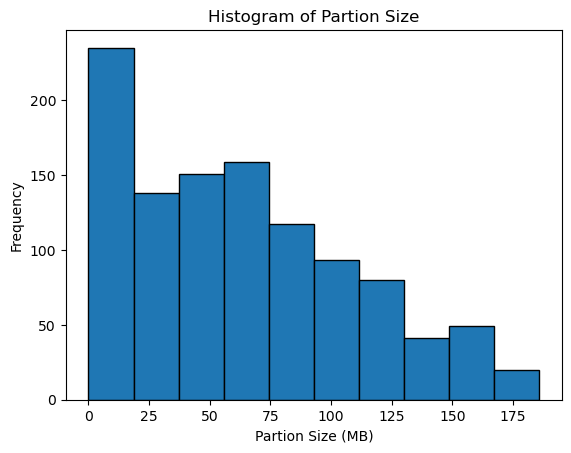
In total at the end of partitioning, I ended up with 1,083 partition files.
Partition Map - Color by file size of partition (MB) #
Partition Stats #